We've recently created a new logging infrastructure for all our Python and C code -- and it's already revolutionizing how we write software.
One of the most critical aspects of developing maintainable software is observability -- do you know what your software is doing? Most of the time we just know the results...which is often fine, until bugs show up. Then it's not uncommon to realize your code is "working" in a manner completely different than you thought.
The most common way to achieve observability is with a good, flexible logging system. The problem with most logging systems is that they are tied to console output, which means you invariably get either too much information (cluttered / unreadable), or not enough. A good logging system will give you fine-grained control over which components have "verbose" logging, which is handy -- except that you have to know in advance what you want to be verbose.
In the process of formulating the design goals of R20S, one of the things we realized is that as long as some care is taken in how logging is implemented, you can always keep detailed logs, and then have them available in retrospect when a problem occurs. So, our logging infrastructure always captures detailed debug logs, tracking them in a rotating buffer / file, so that when a problem occurs, we can access detailed information about what the software was doing right up to the point of the problem. And this isn't just useful for debugging, it also improves your "big-picture understanding" of the code's calling patterns across modules and up-and-down the call stack -- something that developers usually only get if they use profiling tools for optimization.
Combine this insight with uniform collection from multiple sources and a cluttered-but-effective UI, and the result is a logging system that changes how we write software.
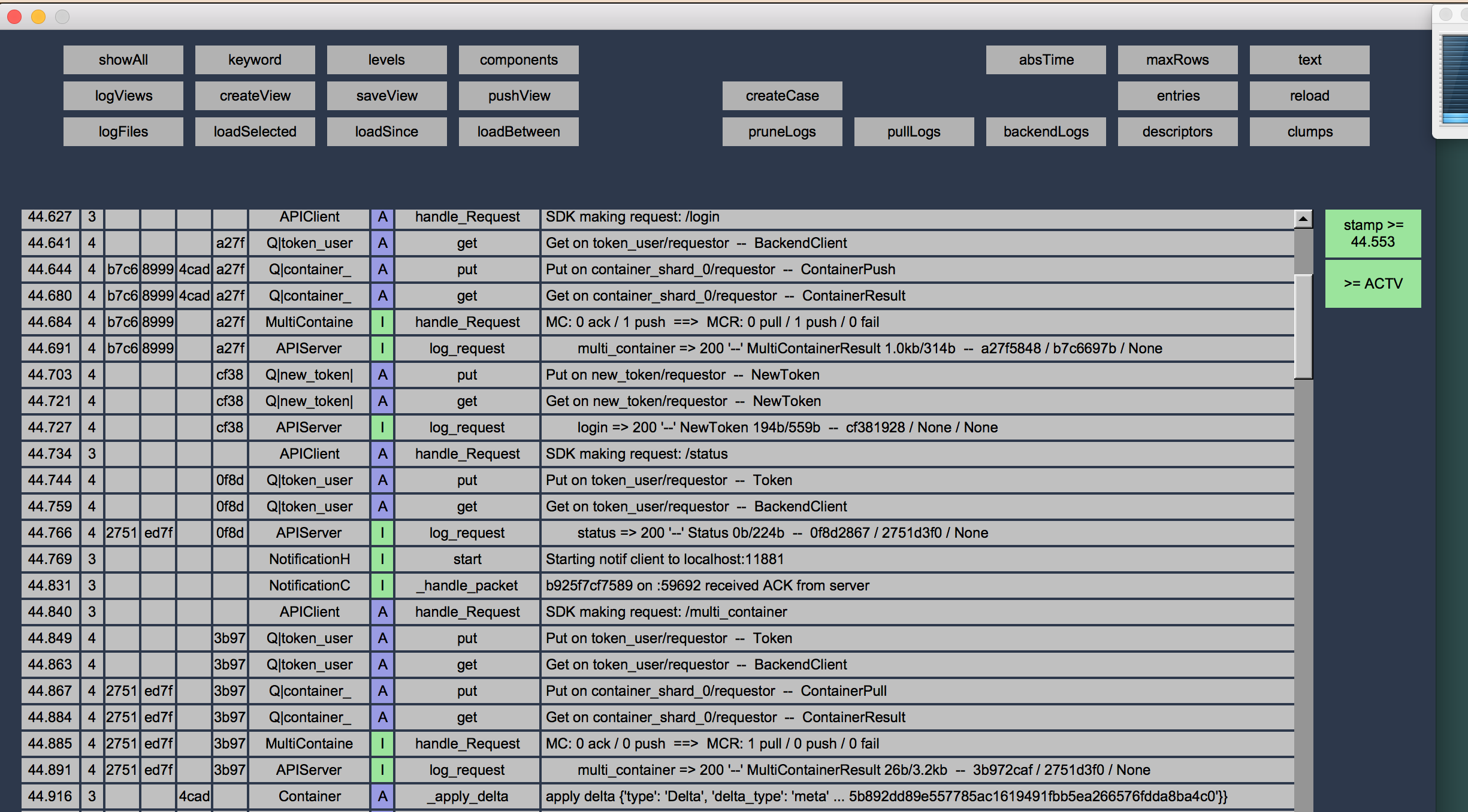
For example, in the development of our CRDT app server, we have several software components running at the same time: on the client side, a frontend UI and the SDK driver; on the backend, several components (potentially on several different machines/instances) that coordinate to provide data synchronization. When a bug occurs, we can now pull logs from both client and server, gather them in one place, and visualize them in a unified UI, allowing us to see the flow of information and activity between the various client and server components.
In other words, we now can see what our software is doing at multiple levels of abstraction instead of guessing or deducing or assuming what it's doing. It's a huge step forward in our software development toolkit.