We do the algorithmics, so you can focus on the science.
- Custom software development / maintenance: Every biotech lab has custom software, often maintained by students -- who come and go, and who would rather be doing biology. We can take over maintenance of your lab-private or open-source repositories, and optimize, clean up, document, and maintain code -- and train new lab members. For more info, see our SPATS case study.
- Illumina Sequencing: We've developed custom algorithms that flexibly handle any experimental template and accurately distinguish between primers, adapters, barcodes/UMI/Index sequences, target sequences, and so on. These handle toggle mutations and indels, and are more accurate and faster than any other tool out there (xref: why you should never trim adapters).
- Custom pipeline creation: We've developed and customized various bioinformatic and statistical modeling techniques (HMMs, clustering, wavelets, etc.), and can tune them for your specific applications and integrate them into your experimental pipeline.
- Sequence Mining: We've developed numerous algorithms that search for any type of sequence motif in DNA/RNA databases (such as PDB, GeneBank, BLAST nr, PFAM, etc), correlating with manual annotations, automated classifications, and experimental data.
- Statistical Analyses and Visualization: Our extensive "Big Data" experience translates directly into bioinformatics, and we are experts and finding statistical irregularities in large datasets and visualizing signal in large and complex datasets.
- Automation: automatically parse and process any type of output format (FASTQ/FASTA, ABIF, SAM, TECAN, PDB, etc. etc.), transforming into CSV/excel/database formats for visualization and analysis.
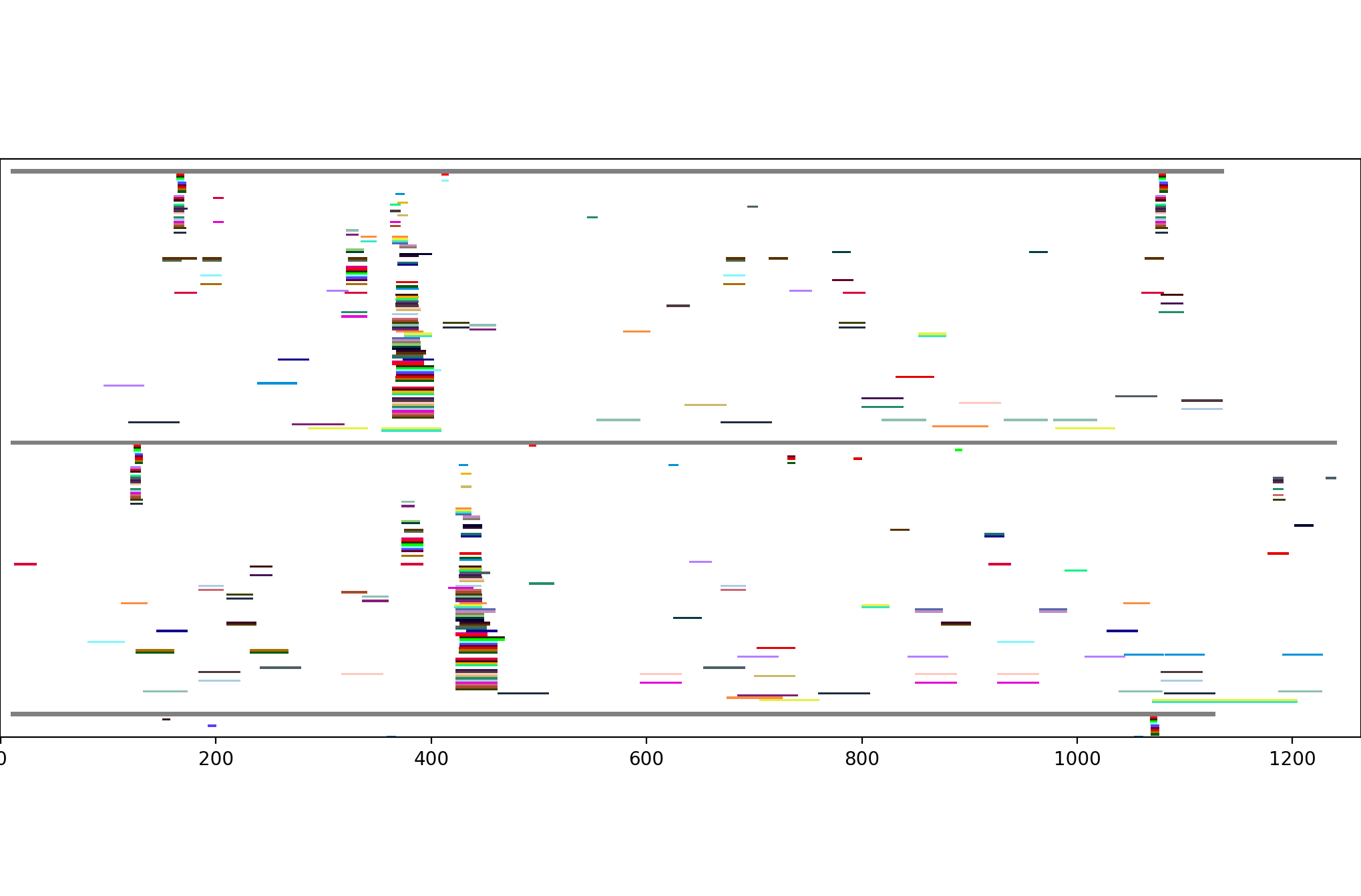
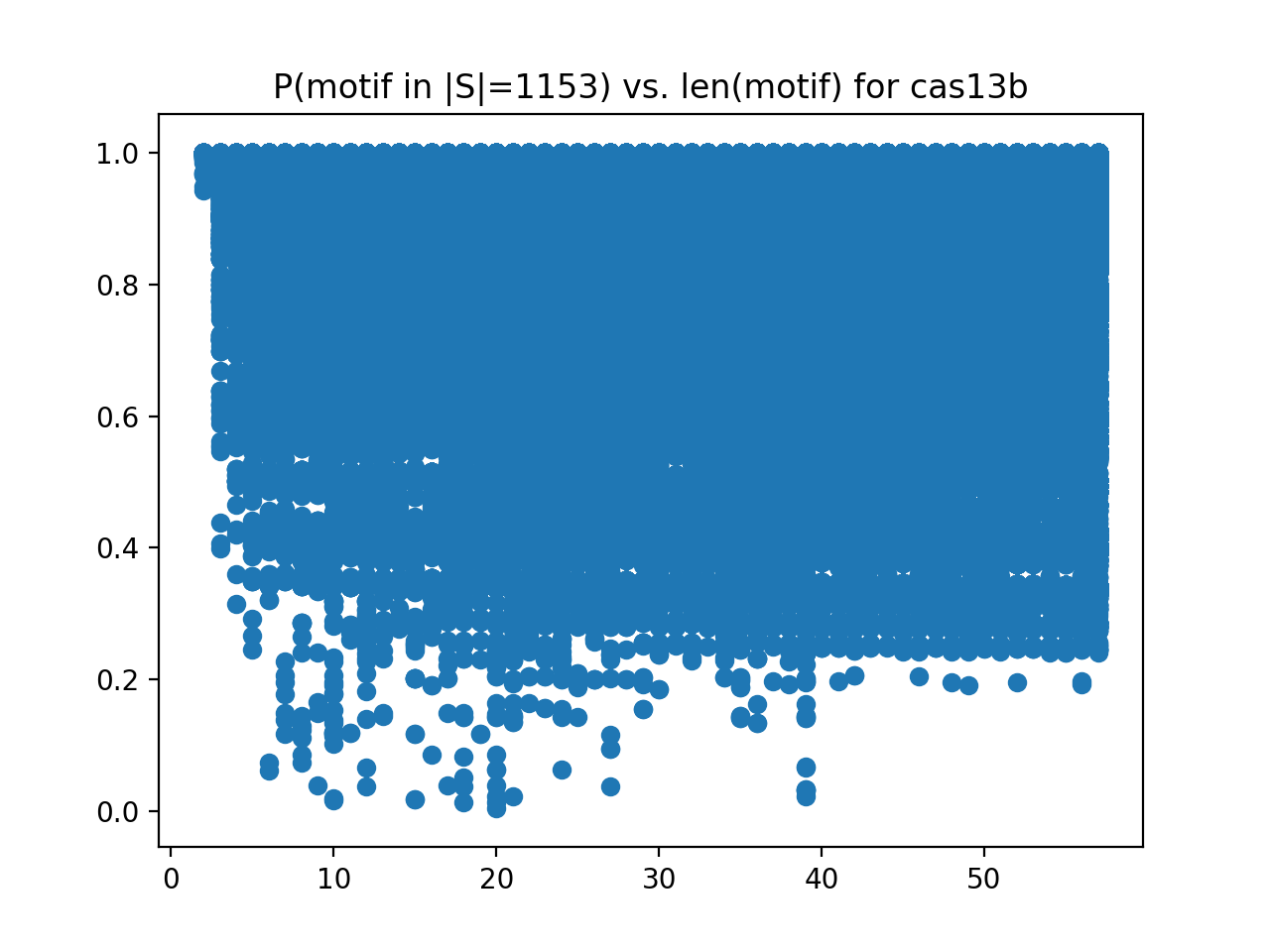
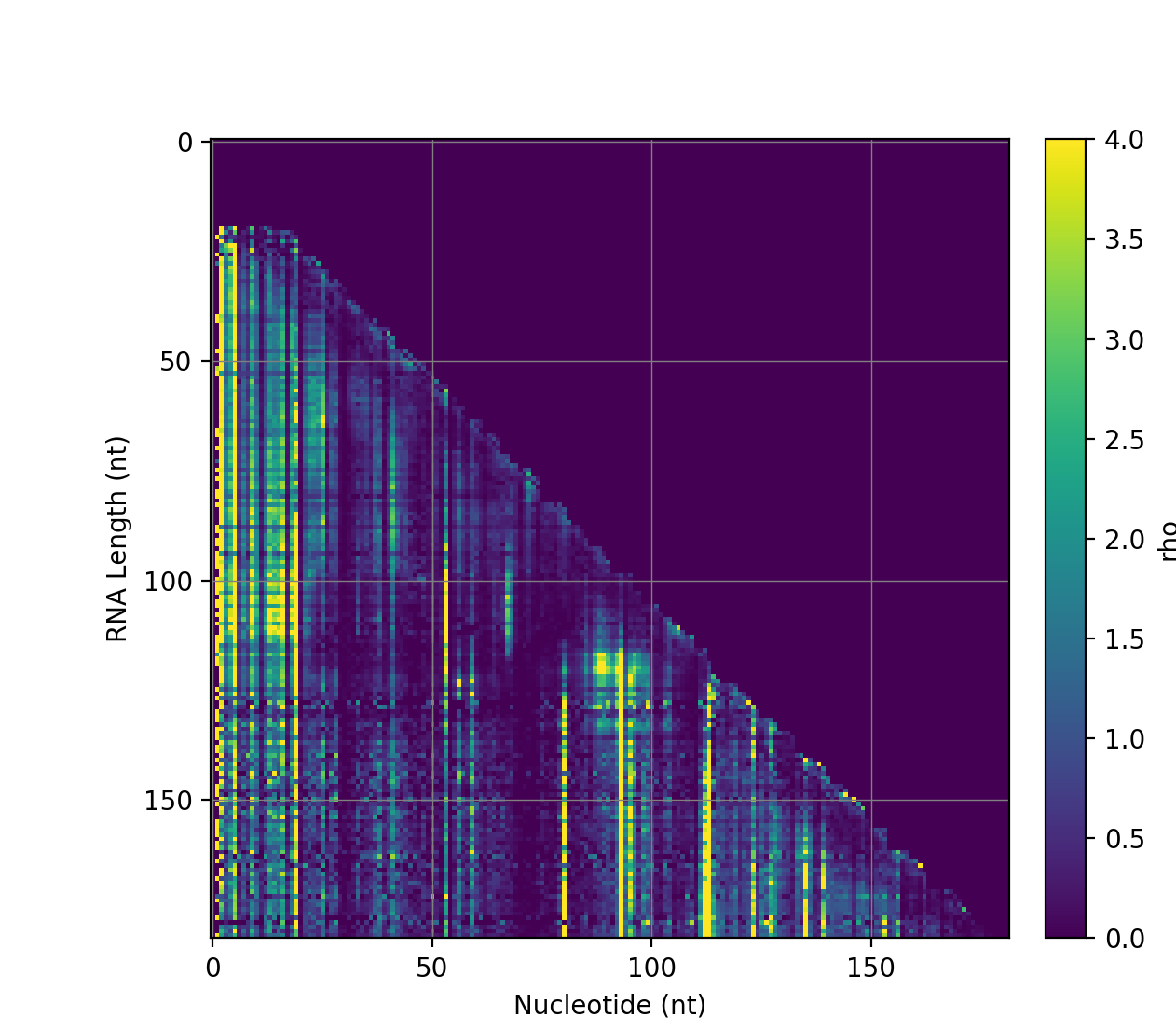
This is just a sample of our experience. We're software engineers by training, but have been focusing on bioinformatics work over the last five years -- and we're looking to do more.
- Discounted rates for EDU
- References available upon request